
When you want a person to do something, you train them. When you want a computer to do something, you program it. However, there are ways to make computers learn, at least in some situations. One technique that makes this possible is the perceptron learning algorithm. A perceptron is a computer simulation of a nerve, and there are various ways to change the perceptron’s behavior based on either example data or a method to determine how good (or bad) some outcome is.
What’s a Perceptron?
I’m no biologist, but apparently a neuron has a bunch of inputs and if the level of those inputs gets to a certain level, the neuron “fires” which means it stimulates the input of another neuron further down the line. Not all inputs are created equally: in the mathematical model of them, they have different weighting. Input A might be on a hair trigger, while it might take inputs B and C on together to wake up the neuron in question.
It is simple enough to model such a thing mathematically and implement it using a computer program. Let’s consider a perceptron that works like a two-input AND gate. The two inputs can be either 0 or 1. The perceptron will have two weights, one for each input, called W0 and W1. Let’s consider the inputs as X0 and X1. The value of the perceptron (V) is then V=X0 W0+X1+W1. Simple, right? There is also a threshold value. If the output value meets or exceeds the threshold, the output is true (corresponding to a neuron firing).
How can this model an AND gate? Suppose you set the threshold value to 1. Then set W0 and W1 both to 0.6. Your truth table now looks like this:
| X1 | X0 | V | Result |
| 0 | 0 | 0*.6+0*.6=0 | 0 |
| 0 | 1 | 0*.6+1*.6=.6 | 0 |
| 1 | 0 | 1*.6+0*.6=.6 | 0 |
| 1 | 1 | 1*.6+1*.6=1.2 | 1 |
If you prefer an OR gate, that’s easy. Just set the weights high enough that it always fires, say 1.1. The value will either be 0, 1.1, or 2.2 and the result is an OR gate.
When It Doesn’t Work
There are two interesting cases where this simple strategy won’t work; we can adopt more complex strategies to fix these cases. First, consider if you wanted a NAND gate. Of course, you could just flip the sense of the threshold. However, if we have any hope of making a system that could learn to be an AND gate, or an OR gate, or a NAND gate, we can’t have special cases like that where we don’t just change the data, we change the algorithm.
So unless you cheat like that, you can’t pick weights that cause 00, 01, and 10 to produce a number over the threshold and then expect 11 to produce a lower number. One simple way to do this is to add a bias to the perceptron’s output. For example, suppose you add 4 to the output of the perceptron (and, remember, adding zero would be the same case as before, so that’s not cheating). Now the weights could be -2 and -2. Then, 00, 01, or 10 will give a value of 4 or 2, both of which exceed the threshold of 1. However, 11 gives a value of zero which is below the threshold.
An easy way to accomplish this is to simply add an input to the perceptron and have it always be a 1. Then you can assign a weight to that input (for example, 0 for the AND gate and 4 for the NAND gate). You don’t have to do it that way, of course, but it makes the code nice and neat since it is just another input.

The white circles are zeros and the black one is the true output. See the straight line that separates the white from the black? The fact that it is possible to draw that line means the AND gate is linearly separable. Setting the weights effectively defines that line and anything on one side of the line is a zero and on the other side is a one.
What about an exclusive OR (XOR)?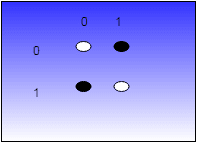
When you have more than two inputs, you don’t have a simple 2D chart like you see above. Instead of defining a line, you are defining a plane or hyperplane that cuts everything cleanly. The principle is the same, but it is a lot harder to draw.
Expanding
For a simple binary output like a logic gate, you really only need one perceptron. However, it is common to use perceptrons to determine multiple outputs. For example, you might feed ten perceptrons image data and use each one to recognize a numeral from 0 to 9. Adding more inputs is trivial and — in the example of the number reader — each output corresponds to a separate perceptron.
Even the logic gate perceptrons could use two separate outputs. One output could be for the zero output and the other could be for the one output. That means the zero output would definitely need the bias because it is essentially a NAND gate.
For example, here’s an AND gate with two parallel perceptrons (assuming a threshold of 1):
| Input | Weight for 0 output | Weight for 1 output |
| X0 | -2 | 0.6 |
| X1 | -2 | 0.6 |
| BIAS (1) | 4 | 0 |
Granted, this is less efficient than the first example, but it is more representative of more complex systems. It is easy enough to select the weights for this by hand, but for something complex, it probably won’t be that easy.
An Excel Model
Before you start coding this in your favorite language, it is instructive to model the whole thing in a spreadsheet like Excel. The basic algorithm is easy enough, but it is interesting to be able to quickly experiment with learning parameters and a spreadsheet will help with that.
I put the spreadsheet you can see below on GitHub. The macros control the training, but all the classification logic occurs in the spreadsheet. The Zero macro and the Train macro are just simple functions. The Train1 subroutine, however, implements the training algorithm.
The weights are the 6 blue boxes from B2:C4. Remember, the last row is the bias input which is always one. The inputs are at E2:E3. E5 is the expected result. You an plug it in manually, or you can use a formula which is currently:
=IF(AND(E2,E3),1,0)
You could replace the AND with OR, for example. You can also change the threshold and training rate. Don’t overwrite the result fields or the other items below that in column B. Also, leave the bias input (E4) as a 1. I protected the cells you shouldn’t change (but if you really want to, the password is “hackaday”).
Learning
How does a system like this learn? For the purpose of this example, I’ll assume you have a set of inputs and you know the output you expect for each (the train macro takes care of that). Here’s the basic algorithm:
- Set the inputs to the test case.
- Look at the expected output perceptron. If its output is not over the threshold, add the scaled input (see below) to the weights in the perceptron.
- Look at the other perceptrons. If their outputs are over the threshold, subtract the scaled input to the weights.
- Repeat the process for each test case.
- Keep repeating the entire set of cases until you don’t have to do anything in an entire set for step 2 and 3.
Scaled input means to take the inputs and multiply them by the training rate (usually a number less than 1). Let’s assume the training rate is 0.5 for the example below.
Consider if all the weights start at 0 and the test case is X0=1, X1=1. The “one” perceptron should fire, but its output is zero. So W0=W0+X0*1*0.5 and W1=W1+X1*1*0.5. In other words, both weights in that column will now be 0.5. Don’t forget the bias input which will be W2=W2+1*0.5.
Now look at the other peceptron. It shouldn’t fire and with an output of zero, it is fine so step 3 doesn’t make any changes. You repeat this with the other test cases and keep going until you don’t have to make any changes for step 2 or 3 for an entire pass.
Here’s the code from the Train1 macro:
' Train one item
Sub Train1()
' Put things in sane names
Stim0 = Range("E2")
Stim1 = Range("E3")
Stim2 = Range("E4") ' should always be 1
Bias = Range("F6")
Threshold = Range("F8")
TrainRate = Range("F9")
Res0 = Range("B5") ' save this so it doesn't "move" when we start changing
Res1 = Range("C5")
Expected = Range("B9")
' If we expected 0 but Res0<Threshold then we need to bump it up by the forula
If Expected = 0 Then
If Res0 =Threshod, we need to bump it down
If Res0 >= Threshold Then
Range("B2") = Range("B2") - Stim0 * TrainRate
Range("B3") = Range("B3") - Stim1 * TrainRate
Range("B4") = Range("B4") - Stim2 * TrainRate
End If
End If
' Same logic for expecting a 1 and Res1
If Expected = 1 Then
If Res1 = Threshold Then
Range("C2") = Range("C2") - Stim0 * TrainRate
Range("C3") = Range("C3") - Stim1 * TrainRate
Range("C4") = Range("C4") - Stim2 * TrainRate
End If
End If
End Sub
' Do training until "done"
Sub Train()
Done = False
ct = 0
Do While Not Done
Done = True
ct = ct + 1
If (ct Mod 100) = 0 Then ' In case bad things happen let user exit every 100 passes
If MsgBox("Continue?", vbYesNo) = vbNo Then Exit Sub
End If
For i = 0 To 1
Range("E2") = i
For j = 0 To 1
Range("E3") = j
' We are not done if there is a wrong answer or if the right answer is not over threshold or if the wrong answer is over the threshold
If Range("B8") Range("B9") Or (Range("B5") Range("B6") And Range("B5") >= Range("F8")) Or (Range("C5") Range("B6") And Range("C5") >= Range("F8")) Or (Range("B6") < Range("F8")) Then
Done = False
Train1
End If
Next j
Next i
Loop
End Sub
' Zero out the matrix
Sub Zero()
Range("B2") = 0
Range("B3") = 0
Range("B4") = 0
Range("C2") = 0
Range("c3") = 0
Range("c4") = 0
End Sub
What’s Next?
Experiment with the spreadsheet. Try an OR, NAND, and NOR gate. Try an XOR gate and note that it won’t converge. There are variations on the algorithm to account for how far off the result is, for example. You can also try initializing the weights to random values instead of zero.
Next time, I’ll show you what this looks like in C++ (suitable for your favorite microcontroller) and talk about how to tackle larger problems. If you want to dig into the theory a little more, you might enjoy [Dan Klein’s] lecture in the video below.
(Banner image courtesy this excellent writeup on neural networks.)
Filed under: software hacks

// from Hackaday http://ift.tt/2fde2vB
site=blogger">IFTTT
EmoticonEmoticon